Critique: Why GPUs are slow at executing NFAs and how to make them faster.
Paper: Liu, Hongyuan, Sreepathi Pai, and Adwait Jog. “Why GPUs are slow at executing NFAs and how to make them faster.” Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems. 2020.
Summary
This paper introduces a new dynamic scheme that effectively balances compute utilization with reduced memory usage for GPUs when executing NFAs. Specifically, the authors identify two performance bottlenecks in the NFA matching process, one is the excessive data movement, the other is poor compute utilization. To tackle these problems, three proposals are demonstrated including 1) using on-chip resources when possible, 2) converting memory accesses to compute 3) mapping only active states to threads. Overall, this study achieves better performance compared with the previous state-of-art GPU implementations of NFAs across a wide range of emerging applications.
In general, this paper focuses on solving a challenge domain-specific problem in the area of GPU. I hold a positive view of the sophisticated scheme and well-designed experiments in this paper for the reason that the methodology and experiments of the article utilize the characteristics of NFA and GPU, and the latter gives sufficient evidence to support these methods. Moreover, to the best of my knowledge, in the context of NFA processing, no prior work has considered both data movement and utilization problems in conjunction. However, it should be noted that there are some trivial flaws in the choice of the comparison method and the organization of the paper is not satisfactory.
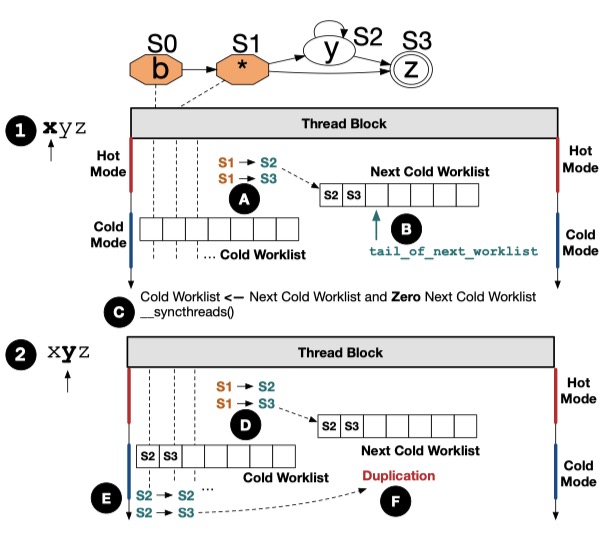
In the following parts, I will analyze the whole paper in detail in terms of writing skills, method design, and experiment, etc.
Strengths
The strengths of the paper have several aspects. First of all, unlike most papers, the title of this paper asked two questions directly which gives an outlook for readers to preview the context of the article directly.
From a high perspective, I think the proposed new data structure to store NFA pattern in this paper is sophisticated and utilize the characteristics of GPU execution since it is challenging for GPUs to obtain enough threads for assigning node data structure which utilizes a 256-bit array of match set, 4 outgoing edges in a 64-bit integer, and an 8-bit array of attributes (3 bits are used to record start state, accept state and always-active state; other 2bits are used for compression). The authors examine the behavior of states and determine which states have high activity frequency and which states have low activity frequency. For example, one of the schemes uses the 1KB prefix of the 1MB input as the profiling input. If a state has an activation frequency more than a threshold in the profiling input, the process considers it as a hot state during the entire execution.
In addition, I think the new data structure can save many redundant spaces which is be of some use for future GPU optimization. In the structure, each node consumes 41 bytes leading to 41N bytes in total compared to 4096N bytes for the alphabet-oriented transition table. Apparently, the scheme only uses 1% space of the traditional table which enables the execution to better exploit the on-chip resources of GPU for topology and the match sets of NFAs.
In terms of the proposed compressing match set, it is intuitively feasible to reduce the number of checking the array of trigger symbols. Specifically, the compressing match set will be marked by the first element and the last element when the arrays have special attributes such as containing a continuous set of bit 1s or a continuous set of bit 0s. When a thread examines a matching set that has that attribute, it can examine in that range instead of checking all the bits. Based on that behavior, high-frequency states will be mapped one-one to threads while the low-frequency states will be stored in a list, and a thread takes responsibility for one or many elements in the list which depends on the available computational resource. Besides, from the beginning to the end of the article, it illustrates the complicated process above by using a simple but comprehensive NFA example that only contains 4 different states. Thus, it is easy for us to understanding and analyzing the whole story to some extent.
Next, as far as I’m concerned, one of the biggest advantages of this paper is that the experiments are detailed and well designed. On one hand, the experiments have designed several evaluation methods which are complete and standardized. These methods contain the characteristics of evaluated NFA applications, throughput enhancement results, absolute throughput with the proposed schemes, effect on data movement reduction, and performance sensitivity to Volta GPU architecture. In particular, all the experimental data gives a convincing analysis. On the other hand, in the appendix of the paper, the authors provide the artifact where there are source code, datasets, workflow, and dependencies, etc. All of them further prove the correctness of the experiment which can provide much convenience for future researchers eventually.
Considering the result of the performance sensitivity to Volta GPU architecture, the proposed schemes (HotStart-MaC and HotStart) show more than 15× speedup over iNFAnt[1], indicating their effectiveness on newer GPU architectures which is a great improvement compared to other methods.
Last but not least, another strength of the article is the proposed method doesn’t contain additional hardware (i.e. hardware-free) to improve the performance of computing NFA-based applications which greatly reduces the cost of deployment and maintenance. Advanced users can easily use the given scheme with the artifact to optimize a specific program.
Weaknesses
When talking about the weakness, the organization or structure of the article should be mentioned first inevitably. The paper including several sections, they are Introduction, background, problem/previous efforts, addressing the data movement problem via match set analysis, addressing the utilization problem via activity analysis, evaluation methodology, experimental results, related work, and conclusions. Obviously, there is redundancy between the chapters which will confuse readers to a certain degree. Sections like background, problem, and previous efforts, and related work can be merged together which provides the preliminaries to the proposed methods. Moreover, the experiments should become an independent chapter including addressing the proposed methods, evaluation methodology, and experimental results rather than splitting them into several independent sections.
Although the experiment is very well designed, its comparison algorithm is old in section 6. For example, iNFAnt[1] and NFA-CG[2] were proposed almost ten years ago which makes the contributions downgraded and unconvincing. Therefore, from my perspective, the paper is supposed to find more comparison methods that maybe not necessarily the application to NFAs to show the advancement of the proposed GPU schemes.
Also, in the experimental part, I find that the effect on data movement reduction isn’t improved a lot, though the utilization optimization reduces the number of thread blocks that access the transition table and the input streams. It can be observed that HotStart (section 5), HotStart-MAC (section 5), NT (section 4.2), and NT-MAC (section 4.3) use 98.9%, 99.3%, 95.9%, and 96.1% gld_transactions respectively while NFA-CG uses 88.2% gld_transactions where the first four names are proposed schemes. One of the possible reasons is that many current methods have improved the data movement reduction to the limitation which is hard to make a great move. Thus, it can be concluded that the data movement reduction is the necessary optimization aspect for NFAs execution. Here, many researchers may consider whether there are more directions for optimization[3] in technique rather than simply reducing data movement.
Furthermore, as a domain-specific paper, the related work (section 8) only demonstrates the work on reducing data movement and improving utilization used in the main process of the newly proposed method. It would be better if the related work could introduce more up-to-date specific methods or GPU accelerators so that readers will have a better understanding of the bottlenecks to improve the throughput of the NFA matching process using GPUs.
Others
As I have said above, the proposed scheme is hardware-free but if we take the throughput into consideration again, we can infer that the performance could be better with the help of hardware/software co-design optimizations to close the remaining gap between hardware and software.
Conclusion
Generally, the work has more strengths than weaknesses. Strengths include the sophisticated data structure and detailed experiments while there are some flaws in the organization of the article and out-of-date comparison methods. In summary, this paper gives a novel way to optimize NFA execution in GPU from the perspective of the software and can guide future work to optimize GPGPU in the aspect of data movement and structure compression.
References
[1] Cascarano, Niccolo, et al. “iNFAnt: NFA pattern matching on GPGPU devices.” ACM SIGCOMM Computer Communication Review 40.5 (2010): 20-26.
[2] Zu, Yuan, et al. “GPU-based NFA implementation for memory efficient high speed regular expression matching.” Proceedings of the 17th ACM SIGPLAN symposium on Principles and Practice of Parallel Programming. 2012.
[3] Vu, Kien Chi. “Accelerating bit-based finite automaton on a GPGPU device.” (2020).
OmegaXYZ is licensed under a CC BY-SA 4.0 Generic License.